Prompt Learning (PL) has emerged as a parameter-efficient technique for adapting Vision-Language Models (VLMs) to downstream tasks. However, almost all existing PL methods are primarily designed and evaluated on well-curated datasets, overlooking a critical post-deployment phenomenon, i.e., the intrinsic connection between input resolution and storage-memory consumption. Specifically, to satisfy the stringent storage-memory constraints on edge devices, models are often limited to low-resolution inputs (e.g., less than 224x224 for CLIP-ViT/B-16) and generate fewer tokens (with the position embedding resized), which poses a unique challenge in performance robustness.
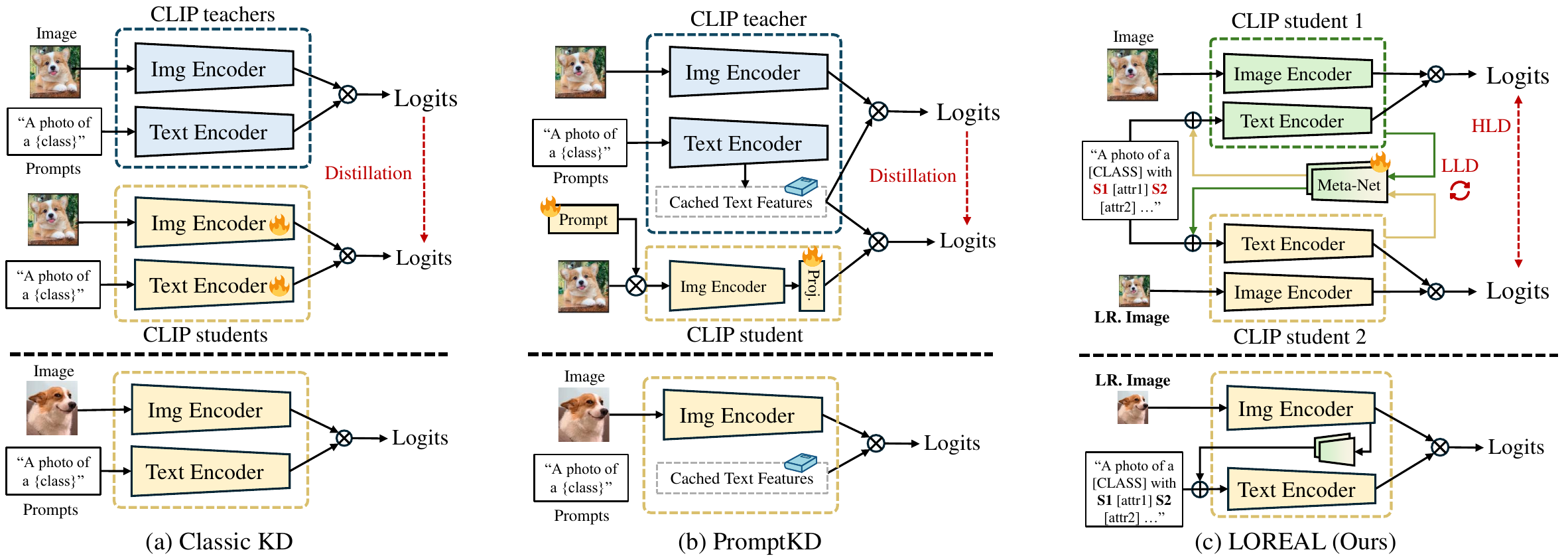
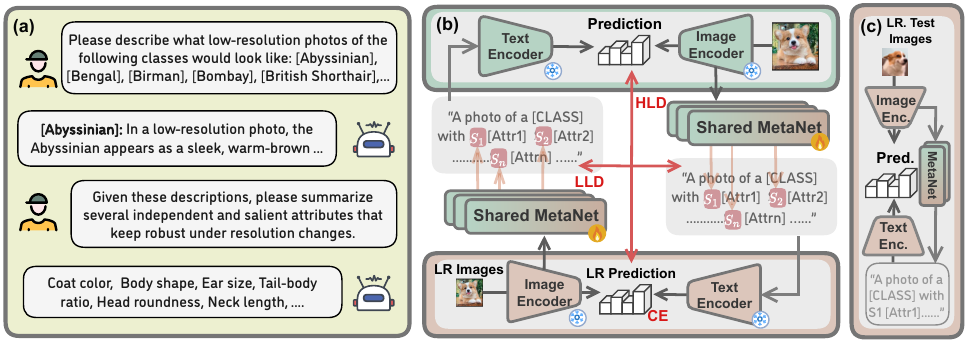
To tackle this issue, we propose LOREAL, an efficient prompt self-distillation framework that learns resolution-invariant representations by excavating attribute semantics. At the heart of LOREAL is a dual-student architecture, i.e., two student models fed with inputs at different resolutions synergistically learn from each other. Building upon this, we contextualize the students' prompt with resolution-invariant attributes queried from the LLM, then leverage cross-modality meta-nets to generate attribute semantics. These meta-nets are bridged between the different encoders of two students, wherein we introduce Low-Level Distillation (LLD) and High-Level Distillation (HLD) to facilitate the learning of more cross-resolution representations. Extensive experiments show that LOREAL significantly improves VLMs' performance and robustness under varied resolution settings, underscoring significant practical utilities.