Abstract
Multi-Label Recognition (MLR) based on Vision-Language Models (VLMs) aims to leverage their pre-trained knowledge to better adapt complex recognition scenarios, thereby enhancing model robustness. However, for realistic decentralized applications requiring federated learning, adapting VLMs to each client that possesses private and heterogeneous data can cause the model to overfit spurious label correlations, consequently triggering irrelevant categories when encountering new samples.
To tackle this problem, we reconsider the federated learning for MLR with a causal model, in which we adopt a front-door adjustment and decouple the MLR modeling process by intermediate variables that magnify the oracle label co-occurrence. Guided by our analysis, we propose our FedMPT, the first method specifically designed for federated MLR. The core idea of FedMPT is to leverage generalizable conditions to steer federated MLR to mitigate erroneous label activations. To achieve this, FedMPT introduces an Large Language Model (LLM)-driven pipeline to decipher the underlying conditions that govern label dependencies. Furthermore, we introduce an optimal transport between the condition-enriched prompts and the image patches to uncover multiple region-level semantics. Finally, we generate synergistic predictions from different conditions with a crafted gating mechanism.
Experiments on multiple benchmark datasets show that our proposed approach achieves competitive results and outperforms SOTA methods under varied settings.
Overview
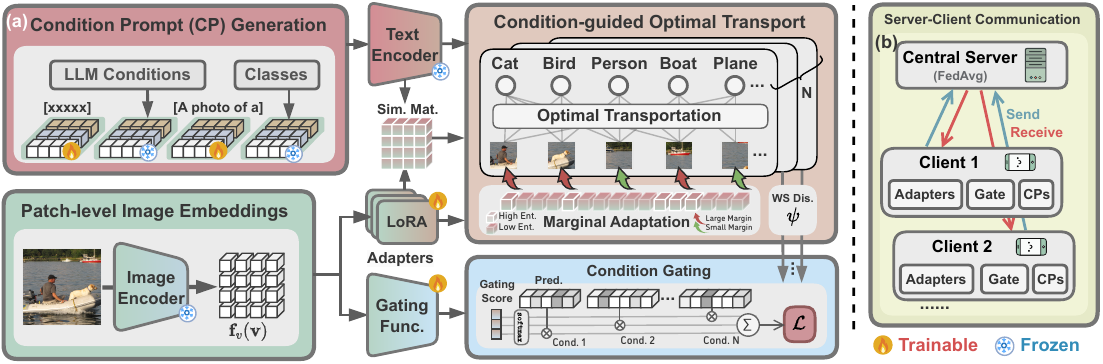
Overview of fedmpt
Overview of our proposed FedMPT framework. (a) The LLM-generated conditions are instantiated into Condition Prompts (CPs), which are encoded into text embeddings. For a given image, its visual feature map is aligned with these prompt embeddings via Optimal Transport (OT). The contributions of different conditions are then adaptively calibrated by a gating module. (b) At each communication round, the server aggregates the parameters of CPs, adapters, and gating modules and distributes the updated parameters back.
FedMPT Efficiency and Adaptability
As in Table 5 of the paper, we compare computation overhead on PASCAL VOC2007 under the same federated multi-label setup (CLIP ViT-B/16). FedMPT reaches the highest mAP while keeping tunable parameters moderate (0.80M)—smaller than Fed-MaPLe (3.56M), FedTPG (4.21M), Fed-RAM (13.02M), and FedMVP (1.14M)—with training time 97.03 ms / iteration, which is higher than the lightest baselines but far below Fed-RAM.
| Method | Total params | Tunable params | Training time | mAP (%) |
|---|---|---|---|---|
| Fed-PosCoOp | 86.60 M | 0.02 M | 38.93 ms/iter | 84.46 |
| Fed-MaPLe | 90.14 M | 3.56 M | 65.25 ms/iter | 81.87 |
| FedTPG | 90.79 M | 4.21 M | 59.43 ms/iter | 84.23 |
| Fed-RAM | 99.60 M | 13.02 M | 384.51 ms/iter | 85.54 |
| FedMVP | 87.72 M | 1.14 M | 75.80 ms/iter | 85.61 |
| FedMPT (Ours) | 87.38 M | 0.80 M | 97.03 ms/iter | 90.10 |
For adaptability, Table 1 varies client data heterogeneity (ratio t ∈ {10%, …, 100%} via clustering-based splits) and reports mAP, per-category F1 (CF1), and overall F1 (OF1). The table below lists the average mAP over all t for representative federated VLM baselines; FedMPT improves over the strong prior FedMVP by +3.84% on VOC2007, +3.01% on COCO2014, and +3.36% on NUS-WIDE in this metric (paper). Table 3 further evaluates a real-world federated MLR setting on Multi-Scene and MLRSNet.
| Method | VOC2007 | COCO2014 | NUS-WIDE |
|---|---|---|---|
| Fed-DualCoOp | 84.94 | 55.63 | 45.00 |
| FedTPG | 85.12 | 58.69 | 50.93 |
| Fed-RAM | 85.67 | 61.08 | 53.33 |
| FedMVP | 85.59 | 61.64 | 52.30 |
| FedMPT (Ours) | 89.51 | 64.65 | 56.69 |
| Method | Multi-Scene | MLRSNet | ||||
|---|---|---|---|---|---|---|
| mAP | CF1 | OF1 | mAP | CF1 | OF1 | |
| Fed-DualCoOp | 40.09 | 31.37 | 50.18 | 38.24 | 40.61 | 66.97 |
| Fed-RAM | 49.41 | 39.07 | 52.70 | 47.83 | 46.07 | 66.18 |
| FedMVP | 49.56 | 39.62 | 54.16 | 45.89 | 44.98 | 66.52 |
| FedMPT (Ours) | 53.68 | 43.97 | 57.83 | 58.76 | 50.86 | 71.22 |
BibTeX
@InProceedings{Wang_2026_CVPR,
author = {Wang, Xucong and Wang, Pengkun and Zhao, Zhe and Yu, Liheng and Wang, Shuang and Wang, Yang},
title = {FedMPT: Federated Multi-Label Prompt Tuning of Vision-Language Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2026},
pages = {17226-17236}
}